
Chess Llama - Training a tiny Llama model to play chess
Inspiration
Large Language Models (LLMs) have dominated the AI landscape for the past few years. Many state-of-the-art LLMs are surprisingly versatile. They can do everything from writing code and articles (including this paragraph) to acting as a romantic companion.
Many of the popular LLMs are also capable of playing chess decently well. There have been multiple articles (like this one) and GitHub repos (like this one) showcasing that.
Then I stumbled upon this blog post by Adam Karvonen. He basically trained a tiny GPT model — Chess GPT — just to play chess. I highly recommend checking out that post and the follow-up research paper, as he visualizes how his chess GPT processes and stores information about the chess board.
Chess GPT is based on the GPT-2 architecture, has a vocabulary of just 32 tokens, and contains up to 50M parameters.
For comparison, Deepseek-V3 has a vocabulary of 129,280 tokens and contains 671B total parameters with 37B activated for each token.
Having read about Chess GPT, my friend and I chose to train a similar model, Chess Llama, built upon the Llama 3 architecture instead of GPT-2.
Gathering the Dataset
Chess Llama is trained on a part of the Lichess Elite database consisting of roughly 3 million games.
I kept the games played between 2019 to 2023 that ended in a checkmate for training data.
Unlike Chess GPT, which uses PGN, I went with UCI notation for representing the games — that is basically the long algebraic notation without piece names.
The games were converted from PGN to UCI notation using pgn-extract.
Here is the Game of the Century in PGN:
1.Nf3 Nf6 2.c4 g6 3.Nc3 Bg7 4.d4 O-O 5.Bf4 d5 6.Qb3 dxc4 7.Qxc4 c6 8.e4 Nbd7 9.Rd1 Nb6 10.Qc5 Bg4 11.Bg5 Na4 12.Qa3 Nxc3 13.bxc3 Nxe4 14.Bxe7 Qb6 15.Bc4 Nxc3 16.Bc5 Rfe8+ 17.Kf1 Be6 18.Bxb6 Bxc4+ 19.Kg1 Ne2+ 20.Kf1 Nxd4+ 21.Kg1 Ne2+ 22.Kf1 Nc3+ 23.Kg1 axb6 24.Qb4 Ra4 25.Qxb6 Nxd1 26.h3 Rxa2 27.Kh2 Nxf2 28.Re1 Rxe1 29.Qd8+ Bf8 30.Nxe1 Bd5 31.Nf3 Ne4 32.Qb8 b5 33.h4 h5 34.Ne5 Kg7 35.Kg1 Bc5+ 36.Kf1 Ng3+ 37.Ke1 Bb4+ 38.Kd1 Bb3+ 39.Kc1 Ne2+ 40.Kb1 Nc3+ 41.Kc1 Rc2# 0-11.Nf3 means that the white player moved his knight to the f3 position.
Here is the same game in UCI:
g1f3 g8f6 c2c4 g7g6 b1c3 f8g7 d2d4 e8g8 c1f4 d7d5 d1b3 d5c4 b3c4 c7c6 e2e4 b8d7 a1d1 d7b6 c4c5 c8g4 f4g5 b6a4 c5a3 a4c3 b2c3 f6e4 g5e7 d8b6 f1c4 e4c3 e7c5 f8e8 e1f1 g4e6 c5b6 e6c4 f1g1 c3e2 g1f1 e2d4 f1g1 d4e2 g1f1 e2c3 f1g1 a7b6 a3b4 a8a4 b4b6 c3d1 h2h3 a4a2 g1h2 d1f2 h1e1 e8e1 b6d8 g7f8 f3e1 c4d5 e1f3 f2e4 d8b8 b7b5 h3h4 h7h5 f3e5 g8g7 h2g1 f8c5 g1f1 e4g3 f1e1 c5b4 e1d1 d5b3 d1c1 g3e2 c1b1 e2c3 b1c1 a2c2 0-1g1f3 means that the white player moved his knight from g1 to f3. This notation does not mention which piece is being moved.
Chess Llama has a vocabulary of 1974 tokens, covering all possible moves in the UCI notation. Each token represents a single move.
This is a big difference compared to Chess GPT, which uses a much smaller vocabulary of 32 tokens — this means that each move in PGN is tokenized into more than one token.
The final processed dataset is available on Huggingface.
If you are curious about how exactly LLMs work, I highly recommend checking out this video by 3Blue1Brown as well as this playlist by Andrej Karpathy.
Training Chess Llama
Chess Llama was trained using the Huggingface Transformers.
The training consisted of 5 epochs with batch size of 16, on a single Nvidia L4 GPU for 18 hours, using the Google Cloud's Vertex AI platform.
Before training, the result of each game is moved to the front of the whole game string, hoping this might help in improving the output quality.
| Hyperparameters | |
|---|---|
| Total Parameters | 23001600 |
| Layers | 8 |
| Model Dimensions | 512 |
| FFN Dimensions | 1024 |
| Attention Heads | 8 |
| Key/Value Heads | 8 |
| Peak Learning Rate | 0.0005 |
| Activation Function | SiLU |
| Vocabulary Size | 1974 |
More training details are available on W&B.
The final model is also available on Huggingface.
You can also try it out here.
Results & Analysis
The model performs with an Elo rating of somewhere between 1350 and 1400. 99.1% moves made by the model were legal. This also means that it managed to figure out the rules of chess by itself, since the training data did not even contain any information about which piece was being moved.
It manages to outperform Stockfish 0 (1350 Elo), but it falls behind Stockfish configured at higher levels.
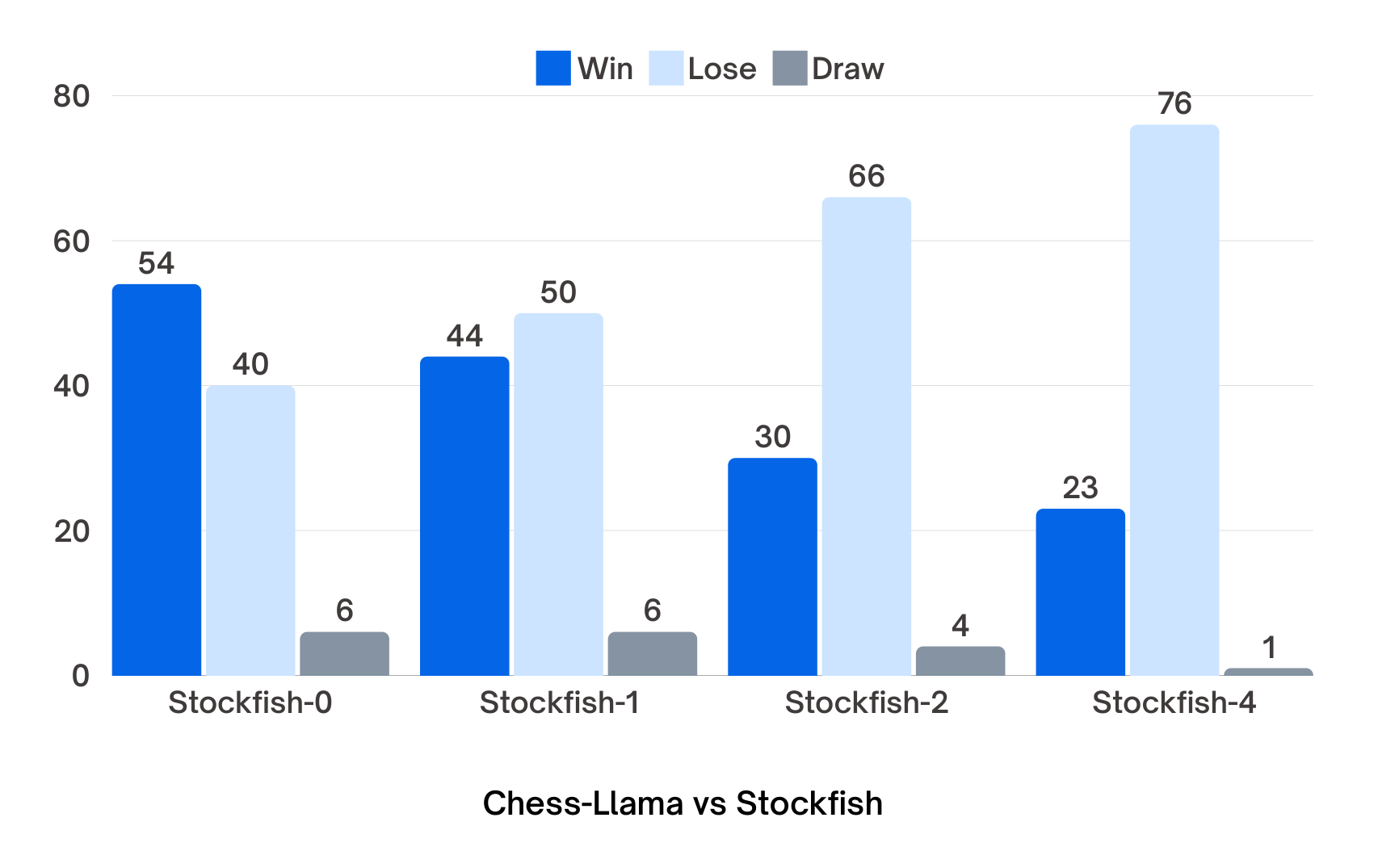
This also means that it performs similarly to the 50M parameter variant of Chess GPT.
Try it out!
You can try it out right in your browser, thanks to Transformers.js!
You can also tweak its skill level thanks to sampling.
The output of Chess Llama (or any decoder-only transformer model) is actually the probability for each token in its vocabulary to be the next token in the game sequence.
By default, Chess Llama plays the most probable move, but there are other ways to pick the next move/token — this process is known as sampling.
The web interface allows you to adjust Chess Llama's sampling configuration, which in turn changes its playing quality. At its default difficulty, the model simply picks the most probable valid move. At the easiest difficulty, it prefers the second most probable valid move.
In the case of LLMs like GPT-4o and Llama 4, proper sampling techniques usually improve the perceived quality and add some randomness to the model's output. But in the case of Chess Llama, it just lobotomizes it.
Future Work
Chess Llama was just a fun side project for me and one of my friends. There is not much left for me to do with it.
I might try deep-diving into how it keeps the track of board state and maybe even try manipulating it, just like the creator of Chess GPT did.